Fake News Detection using NLP and Machine Learning Techniques

Abstract
Fake news has become a pervasive issue in today's digital landscape, with the potential to significantly influence public opinion, shape political discourse, and even impact democratic processes. This project addresses the challenge of fake news detection by leveraging natural language processing (NLP) techniques and machine learning algorithms. Through comprehensive exploration and evaluation of different feature engineering methods and classification algorithms, the project aims to develop robust models capable of accurately distinguishing between real and fake news articles.
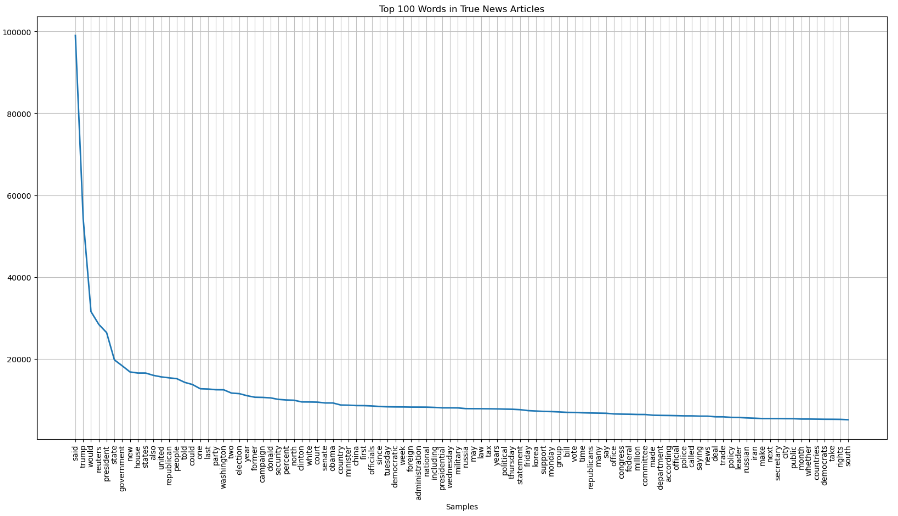
Top 100 words in True news.

Dataset after cleaning using tokenizer, stop words removal, lemmatizing and stemming, POS Tagging.
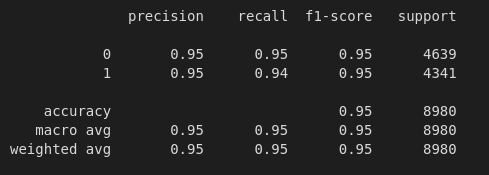
Results using Naive Bayes Bag of Words
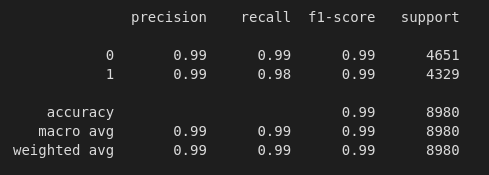
Results using Random Forest Bag of Words
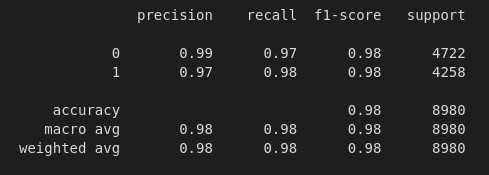
Results using Decision Tree Bag of Words
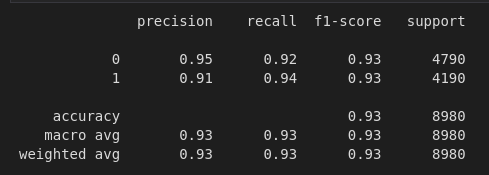
Results using Naive Bayes TFIDF
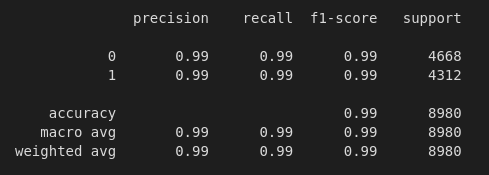
Results using Random Forest TFIDF
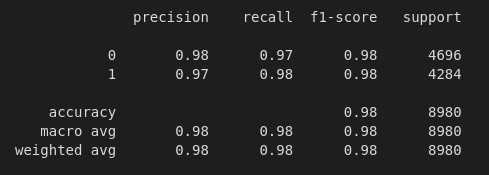
Results using Decision tree TFIDF
Introduction
The advent of social media and online platforms has facilitated the rapid dissemination of information, including fake news and misinformation. The proliferation of such content poses serious threats to societal well-being, including the erosion of trust in media, polarization of public discourse, and potential manipulation of public opinion. Detecting and combating fake news has thus emerged as a critical endeavor, requiring innovative technological solutions. In this context, machine learning techniques offer promising avenues for automatically identifying fake news articles based on their linguistic characteristics and contextual features. This project seeks to contribute to this important area of research by investigating the effectiveness of NLP techniques and machine learning algorithms in detecting fake news.
Methodologies
-
Data Preprocessing:
The initial phase of the project involves preprocessing the news article dataset to ensure its suitability for analysis. This includes cleaning steps such as removing HTML tags, handling missing values, and performing text normalization to standardize the textual data. -
Feature Engineering:
Following data preprocessing, the project explores various feature engineering techniques to extract informative features from the text data. This includes traditional methods such as Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF), as well as enhanced NLP techniques such as extracting only nouns and adjectives from the text. -
Machine Learning Algorithms:
Once the features are extracted, the project employs several machine learning algorithms for the classification task. These include Naive Bayes, Random Forest, and Decision Tree classifiers, each of which offers different advantages and trade-offs in terms of model complexity and performance. -
Model Evaluation:
The trained models are evaluated using standard performance metrics such as accuracy, precision, recall, and F1-score on a held-out test set. This evaluation provides insights into the effectiveness of each approach in accurately classifying news articles as real or fake. -
Model Comparison:
The project compares the performance of different models and feature engineering techniques to identify the most effective approach for fake news detection. This comparative analysis helps to understand the relative strengths and weaknesses of each method and informs recommendations for future research and application.
Results
The results section of the project presents a detailed analysis of the performance of the various machine learning models and feature engineering techniques employed. Metrics such as accuracy, precision, recall, and F1-score are reported for both the training and test sets, providing a comprehensive overview of each approach's effectiveness. The results highlight the relative performance of different models and feature engineering methods, enabling stakeholders to make informed decisions about the most suitable approach for fake news detection.
Overall, this project contributes to the ongoing efforts to combat fake news and misinformation by leveraging advanced NLP techniques and machine learning algorithms. By providing a systematic evaluation of different approaches and their performance, this work aims to empower stakeholders with effective tools for identifying and mitigating the impact of fake news on society.
Portfolio
Find my projects on my github profile.