Neural Radiance Fields

Abstract
This report explores the Neural Radiance Fields (NeRF) technique, an advanced neural rendering method used to generate novel scenes using ground truth poses and images as input. The NeRF model leverages neural networks to represent complex radiance and appearance, producing realistic renderings with RGB colors and output density. The study applies the NeRF framework to the Lego bulldozer dataset, partitioning it for training, validation, and testing. By analyzing ray generation, stratification, positional encoding, and model architecture, the report demonstrates the process of volume rendering and its applications in various fields. The results highlight the model's performance and propose potential enhancements, such as extended training duration and hierarchical volume sampling, to improve the visual fidelity and sharpness of the generated images.
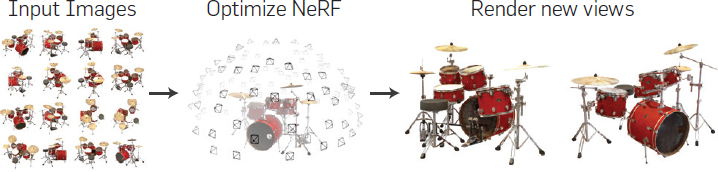
View Synthesis. Source: NeRF at ICCV 2021

Dataset Images

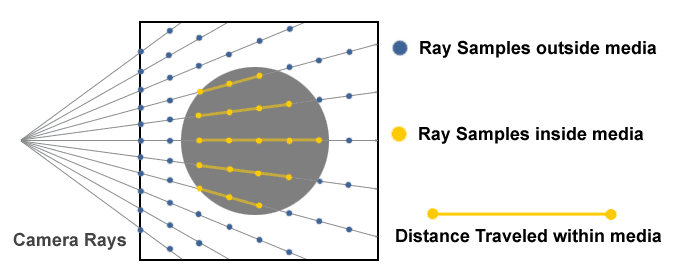
Ray Generation and Stratification. Source: Creating a Volumetric Ray Marcher by Ryan Brucks

Positional Encoding Source: Learning high frequencies with Fourier feature mapping
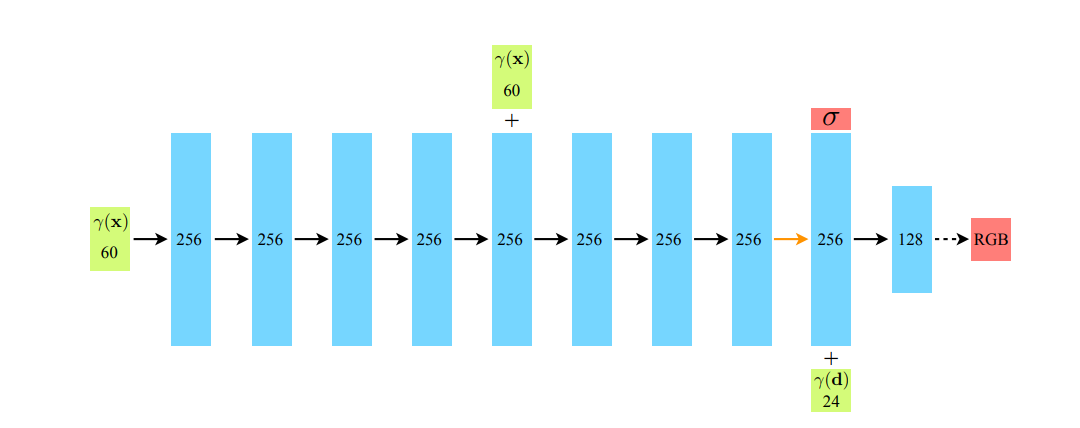
Model for NeRF
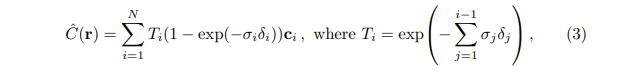
Volume rendering

Output
Introduction
NeRF, short for Neural Radiance Fields, is an advanced neural rendering technique that enables the generation of novel scenes by utilizing ground truth poses and their image perspectives as input. By optimizing the model based on these input poses, NeRF becomes capable of functioning as a function approximator for any given pose within the scene. In essence, NeRF has the ability to provide fresh perspectives of objects when provided with input views of those objects.
The input to the NeRF model consists of a 5D tensor, encompassing spatial location (x, y, z) and viewing direction (θ and ψ) information. The output of the model comprises RGB colors and output density, allowing for the synthesis of realistic and visually appealing renderings. This sophisticated approach leverages neural networks to capture and represent the complex radiance and appearance of objects, enabling the generation of high-quality images from various viewpoints.
Dataset
For the conducted experiments, a specific dataset called the Lego bulldozer dataset was employed. The dataset was obtained in the form of a NumPy file and consisted of a total of 106 images, each accompanied by its respective pose information. From this dataset, a training set comprising 100 poses was selected, ensuring a diverse representation of viewpoints and object configurations. To evaluate the performance and generalization capabilities of our model during the training process, one pose was reserved for validation purposes. Furthermore, five poses were specifically set aside to establish a dedicated testing set, which served as a benchmark for assessing the final performance and accuracy of our trained model. By meticulously partitioning the dataset into distinct subsets, the main intention is to facilitate rigorous experimentation and ensure reliable evaluation of the proposed methods.
Ray Generation
In the NeRF (Neural Radiance Fields) framework, ray-based computations play a crucial role, necessitating a clear understanding of how rays are generated for each pose. To achieve this, a comprehensive understanding of the camera's position and rotation matrix, derived from the pose matrix, is essential. This knowledge enables the determination of ray directions for every pixel in the image, taking into account the principles governing the pinhole camera model. Specifically, it involves calculating the directions of the rays with respect to the camera frame. By utilizing the rotation matrix, these ray representations can be transformed to the world frame. The "get rays" function in our code assumes the responsibility of executing these critical computations, playing a pivotal role in facilitating the ray-based operations within the NeRF framework.
Ray Stratification
In order to approximate the sampling of each point along a ray, a practical approach involves utilizing a discrete set of points on the ray. Although achieving a truly continuous sampling is unfeasible, random points are generated within the range defined by the two endpoints of the ray. These endpoints are selected arbitrarily for the purpose of stratification. The implementation of this stratification technique can be found in the "get stratified" method.
Positional Encoding
The incorporation of Positional Encoding plays a pivotal role in the NeRF implementation, as highlighted in the paper. The paper underscores the challenge faced by neural networks in effectively handling high-frequency inputs. To address this limitation, the paper proposes the utilization of Positional Encoding, which involves modulating the raw input with sine and cosine frequency bands. In accordance with the paper's recommendation, we have adopted the setting of 10 frequency bands for the spatial component and 4 frequency bands for the viewing directions component. This adherence to the paper's guidelines ensures the appropriate integration of Positional Encoding within our NeRF framework.
Model Architecture
The implemented architecture closely follows the proposed NeRF architecture as outlined in the research paper. The input of the network consists of the spatial information, which is processed through an MLP comprising eight layers. Notably, on the fourth layer of the MLP, the spatial input is reintroduced as a skip connection to facilitate information flow. Subsequently, a linear layer is applied as the ninth layer, producing a one-dimensional output density logit with ReLU activation. For the RGB outputs, the ninth layer is concatenated with the input representing viewing directions. The eleventh layer serves as the output layer, employing a sigmoid activation function to generate the RGB values. The eighth and ninth layers indicates no activation function is applied. Throughout the architecture, ReLU activations are utilized, except for the specified cases.
Volume Rendering
Volume rendering is a powerful technique that allows the creation of visually appealing 2D projections from volumetric datasets, which are typically obtained through discrete sampling in 3D space. In volume rendering, an algorithm is employed to determine the RGBα values (representing Red, Green, Blue, and Alpha channels) for each voxel along the rays casted from a given camera position. These RGBα values are then converted to RGB colors and assigned to the corresponding pixels in the resulting 2D image. This process is iterated for each pixel, progressively rendering the entire 2D image.
By applying volume rendering, complex volumetric data can be effectively visualized and understood in a 2D representation. this technique finds applications in various fields such as medical imaging, scientific visualization, and computer graphics, enabling researchers and professionals to gain valuable insights from volumetric datasets. The formula on the right performs volume rendering, This equation basically sums up the RGB values across views according to the output density.
Results and Possible Improvements
The NeRF model was trained for a total of 7500 iterations, with each iteration incorporating only one pose as input. To accommodate the computational limitations of the GPU, the number of rays provided to the model was batched. This approach enabled the model to handle the image rays efficiently. Notably, the training process required approximately 7 hours on the university cluster, reflecting the computational demands of the NeRF model. For the evaluation of the trained NeRF network, the four test poses were used as input. By comparing the generated color map of the model with the corresponding ground truth image, we assessed the quality of the model's predictions.
We propose two potential enhancements: Firstly, extending the training duration by significantly increasing the number of iterations. In the original NeRF paper, the network was trained for 200,000 iterations, suggesting that a more extended training period could yield better results. Secondly, incorporating Hierarchical Volume Sampling into the training process could help enhance the reconstruction of textures in the generated images. By adopting these measures, we anticipate improvements in the visual fidelity and sharpness of the NeRF model's outputs.
Portfolio
Find my projects on my github profile.